What is OpenAI GPT-4o Audio Models?
New OpenAI audio models for developers: gpt-4o powered speech-to-text (more accurate than Whisper) and steerable text-to-speech. Build voice agents, transcriptions, and more.
Problem
Users previously relied on less accurate speech-to-text models like Whisper and limited text-to-speech customization, leading to errors in transcription and robotic voice outputs.
Solution
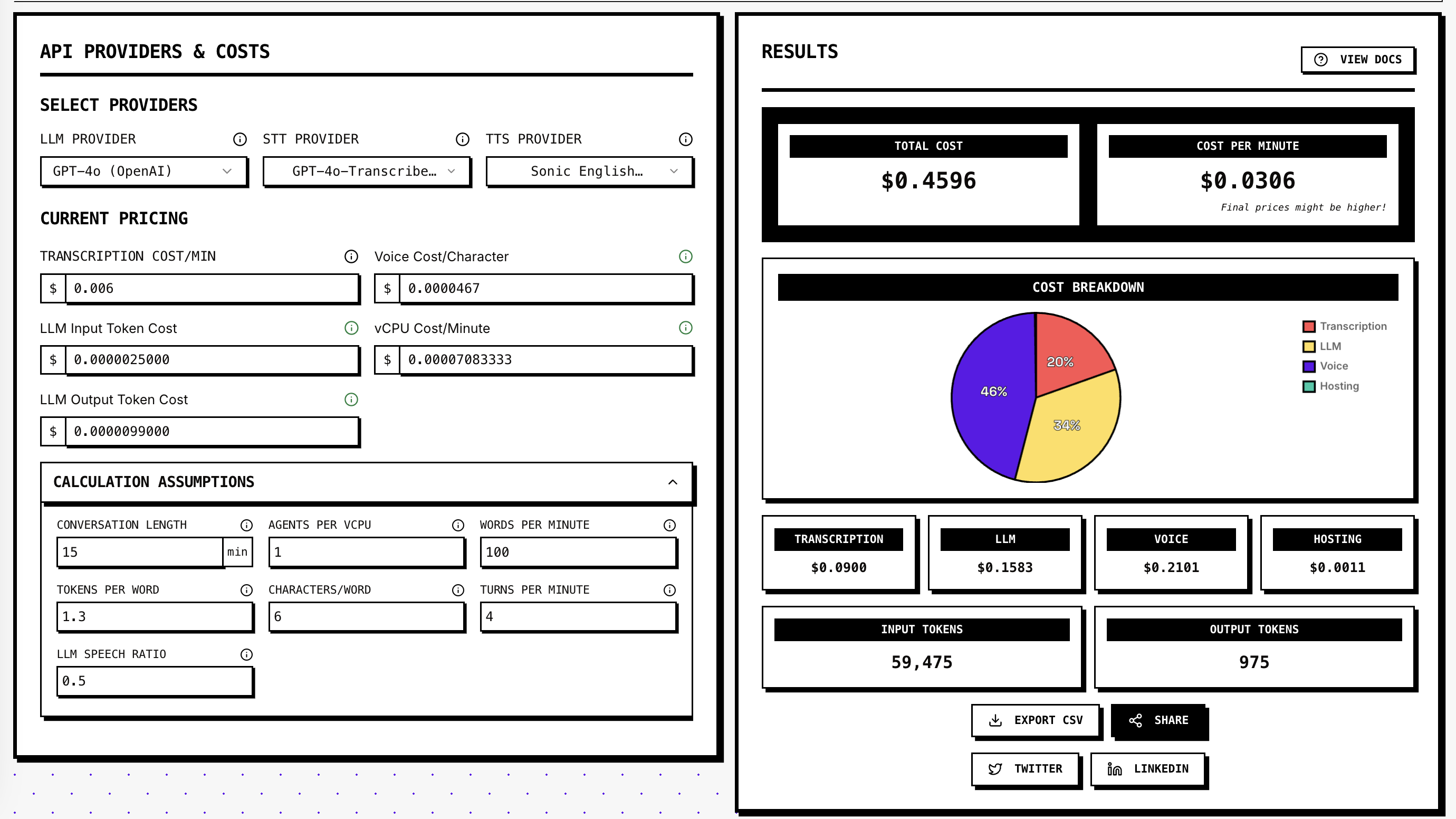
API-based audio models enabling developers to build voice agents, transcribe audio, and generate steerable text-to-speech (e.g., real-time customer service bots, multilingual transcription tools).
Customers
AI developers, voice app engineers, and tech startups focused on voice-enabled products.
Unique Features
GPT-4o-powered contextual understanding, higher speech-to-text accuracy than Whisper, and dynamic voice modulation controls.
User Comments
Outperforms Whisper in noisy environments
Easy API integration for voice features
Customizable voice tones boost user engagement
Cost-effective for scalable projects
Supports multiple languages seamlessly
Traction
Used by 3M+ OpenAI API developers; GPT-4o adoption details undisclosed, but 600+ ProductHunt upvotes within 24 hours.
Market Size
The global speech and voice recognition market is projected to reach $50 billion by 2029 (Allied Market Research, 2023).